CONCEPTS OF GOOD AND EVIL IN A NEURAL NETWORK APPROACH
CONCEPTS OF GOOD AND EVIL IN A NEURAL NETWORK APPROACH
Abstract
In this work, neural networks and the possibility of using the PCA algorithm (principal component analysis) to analyse clusters of words on the topics of ethics (good and evil) and aesthetics (beautiful-pretty) in a multidimensional semantic space were examined. PCA algorithm identifies two main directions in the clusters which, are visualized on the graph as the X-axis and Y-axis. The visualization clearly shows 4 clusters, which confirms that the clusters are actually present in the language. There is also a direction connecting the centres of these clusters, which forms a quantitative multiband scale to assess aesthetic tonality (beautiful-pretty-0-ugly-horrible) and to evaluate ethical tonality (kindness-goodness-0-evil-hate-crime-murder). Such scales can be used to monitor the ethical and aesthetic tonality of texts.
1. Введение
Концепты «добро» и «зло» лежат в основе понятий «ценность», «мораль», «этика». Добро и зло как морально-этические категории, на которых базируется нравственная оценка, занимают особое, ведущее место в иерархии моральных ценностей, поскольку именно различение добра и зла является определяющим в нравственном сознании человека
.Задача статьи – это ответ на вопрос может ли программа различать добро и зло, т.е. этическую тональность текста или слова. Этическая составляющая, выраженная на уровне лексемы/слова, называется лексической тональностью. Этическая тональность текста в целом определяется лексической тональностью составляющих его единиц и правилами их сочетания. Автоматический анализ этической тональности текстов мог бы быть полезен в образовании и школьном воспитании для анализа учебных материалов и планов.
Вопросам добра и зла посвящено много статей в философии, филологии, культурологии, лингвистике. В этих статьях исследователи рассмотрели слова и понятия, связанные с добром и злом, а также сложные взаимосвязи этих слов и понятий. В данной статье добро и зло рассматриваются с точки зрения компьютерной лингвистики и нейронных сетей. При этом семантическая близость между словами рассчитывается автоматически с помощью нейронных сетей по большому корпусу текстов, содержащему до миллиарда слов. Нейронная сеть рассчитывает семантическую близость между словами путем сравнения контекстов этих слов. Т.к. слова обычно имеют несколько значений, то для анализа этих значений используются группы/кластеры семантически близких слов. При таком рассмотрении понятию/концепту соответствует группа/кластер семантически близких слов, имеющих общую часть значения которая совпадает с этим понятием. Например, понятию добро (или зло) соответствуют группа/кластер семантически близких слов, общей частью значения которых служит концепт добра (или зла). Вопрос «может ли программа различать добро и зло» – сводится к вопросу «можно ли автоматически разделить кластеры добра и зла». Если эти кластеры разделяются, то возникают дополнительные вопросы. Какие слова, ассоциативно/семантически связанные с добром, меньше связаны со злом? Какие слова, ассоциативно/семантически связанные со злом, меньше связаны с добром? Существует ли ось, или направление, проходящее между кластерами добра и зла, и соответствующая шкала?
В данной работе вопрос «можно ли разделить кластеры добра и зла» решается путем визуального анализа семантической близости между словами c помощью алгоритма визуализации PCA.
2. Обзор
Понятия добра и зла являются междисциплинарными и рассматриваются с позиций религии, философии, филологии, культурологии и лингвистики. В данном обзоре основной упор делается на выявление слов, связанных с понятиями добра и зла, без анализа сложных взаимосвязей между этими словами. Выявленные слова в разделе 5 будут использованы для визуализации и анализа кластеров.
2.1. ФИЛОСОФИЯ. С точки зрения философии Добро и Зло – это основные категории этики, обозначающие, с одной стороны, то, чего субъект стремится достичь (благо) или избежать (зло) в своей деятельности, с другой – нравственная правильность или неправильность (должный или недолжный характер) того или иного действия либо направления воли
.2.2. ЛИНГВИСТИКА. Концепты «добро» и «зло» также являются объектом исследования лингвистики. В фундаментальном труде Н.Д. Арутюновой
дается классификация оценок, в которой общая оценка (хороший – плохой) противопоставляется частным, среди которых выделяются три группы:1) сенсорные оценки;
2) сублимированные оценки;
3) рационалистические оценки.
Этические оценки (моральный – аморальный, нравственный – безнравственный, добрый – злой, добродетельный – порочный), как и эстетические (красивый – некрасивый, прекрасный – безобразный, уродливый) относятся к сублимированным. Хотя эстетические оценки вытекают из синтеза сенсорных (гедонистических и психологических), они возвышаются над последними, «гуманизируя» их
. Л.А. Блинова, Н.А. Купина выделяют следующие группы этических концептов, представляющих общечеловеческие духовные ценности:1) нравственность, мораль, этика;
2) правда, истина;
3) духовность, дух, душа;
4) гуманизм, человечность;
5) совесть, совестливость;
6) счастье.
Как мы видим, полного согласия между лингвистами относительно границ области этических концептов и класса выражающих их слов нет. Хотя большинство этических концептов, выделенных в
, соответствует понятию этических оценок в , но концепт ‘правда, истина’ (на самом деле, в русской языковой картине мира это два разных концепта, из которых ‘правда’ ближе к области этики) относится не столько к сфере этики, сколько к сфере познания мира (гносеологии) . Однако скрещение истинностной и этической оценок происходит практически всегда, когда речь идет о поведении людей и событиях их жизни . Концепт же ‘счастье’ согласно классификации в был бы отнесен к оценке, в которой синтезируются гедонистические, психологические и этические мотивировки.2.3. ЛИНГВОКУЛЬТУРОЛОГИЯ. Добро и зло часто анализируются с позиции лингвокультурологии. Так, например, в работах
, , вместе с понятиями добра и зла рассматриваются такие связанные с ними слова как любовь, благополучие, счастье, добродетель, доброта, смерть, ненависть. Эти слова мы использовали для визуализации связей в разделе 5.2.4. КОМПЬЮТЕРНАЯ ЛИНГВИСТИКА. Используя методы компьютерной лингвистики, Ананьева М.И., Кобозева М.В., Соловьев Ф.Н., Поляков И.В., Чеповский А.М.
анализировали проблему выявления экстремистской направленности в текстах. Экстремизм связан с ненавистью, агрессией и злом. Для выявления экстремизма использовался словарь терминов, употребление которых в тексте может свидетельствовать о наличии агрессии. Отмечалось, что разработанные методики опираются в основном на словарные системы, что ограничивает их применение в реальных информационных системах, требующих огромных затрат на актуализацию словарей.В зарубежной компьютерной лингвистике работы, близкие по тематике к выявлению добра и зла, используют метод многомерного тонального анализа. Анализ тональности текста (сентимент-анализ, Sentiment analysis) используется для автоматизированного выявления в текстах эмоционально окрашенной лексики. В современных системах автоматического определения эмоциональной оценки текста чаще всего используется одномерное пространство: позитив или негатив (хорошо или плохо). Однако известны успешные случаи использования и многомерных пространств, среди которых есть, в частности, и направление добрый – злой.
Так, в работе
описан эксперимент по определению эмоциональной тональности заголовков новостей. Этот эксперимент основан на экономичном (в плане лексики) подходе к определению тональности на основе модели пространства слов и набора базисных слов. Модель обучалась на газетных новостях, а тональность вычислялась с использованием близости к одной из двух базисных точек, заданных вручную в многомерном словесном пространстве — одна представляла положительную тональность, другая — отрицательную тональность. Спроецировав каждый заголовок в это пространство, выбрав в качестве тональности показатель сходства с базисной точкой, которая была ближе к заголовку, эксперимент дал результаты с высокой точностью распознавания отрицательных и положительных заголовков. Эти результаты показывают, что работа с ограниченной лексикой является жизнеспособным подходом к контент-анализу текстовых данных. В работе использовались следующие базисные слова для создания векторов тональности: положительный – отрицательный, хороший – плохой, победа – поражение, успех – бедствие, мир – война, счастливый – грустный, здоровый – больной, безопасный – опасный.По аналогии с алгоритмом Салгрена в 2010 Google создал собственный инструмент: Google-Profile Of Mood States (GPOMS) с расширенным лексиконом, который может измерять состояния человеческого настроения в шести измерениях настроения: Спокойствие, Настороженность, Верный, Витальный, Добрый и Счастливый.
В статье
для прогноза рынка анализируется текстовое содержимое ежедневных лент Twitter с помощью двух инструментов отслеживания настроения, а именно OpinionFinder, который измеряет позитивное и негативное настроение, и Google-профиль состояний настроения (GPOMS), который оценивает настроение по 6 параметрам/измерениям: Спокойный, Бдительный, Уверенный, Жизненно важный, Добрый и Счастливый. Результаты показывают, что точность прогнозов Доу-Джонса может быть значительно повышена за счет включения одних параметров общественного настроения, но не других.По аналогии с системой Сальгрена и GPOMS могут быть созданы системы для определения многомерной тональности текстов содержащие десятки измерений, включая Добро-Зло. Для этого нужно расширить базисный лексикон, задающий направления, а также использовать современные семантические векторные пространства, основанные на нейронных сетях, таких как Word2Vec или BERT. Для более точного задания направления в семантическом пространстве слов можно использовать не пары базисных слов, а целые кластеры из близких по смыслу слов.
3. Нейронная сеть. Термины, которые в нее вводились
В данной работе для проведения экспериментов использовался сервис RusVectōrēs на сайте rusvectores.org, созданный А. Кутузовым , который вычисляет семантические отношения между словами русского языка и может работать с лексическими векторами. Лексические вектора представляют значение слова в многомерном пространстве их контекстов. Лексические вектора автоматически строятся на основе статистики совместной встречаемости различных слов в больших коллекциях текстовых данных. Семантическое сходство между словами вычисляется на основе близости их лексических векторов. Процесс построения лексических векторов и векторных моделей по большим коллекциям текстов называется обучением. Для такого обучения часто применяют искусственные нейронные сети на основе предсказания соседних слов. При этом используются методы оптимизации точности предсказания по миллионам параметров. В результате семантика слов представляется сжатыми векторами, которые можно использовать для самых разных компьютерно-лингвистических задач. Один из первых и наиболее известный на сегодня инструмент в этой области — Word2Vec, но регулярно появляются новые алгоритмы и модели, например, BERT. Следует отметить, что процесс обучения и построения векторных моделей – это очень длительный процесс, который может занимать несколько дней. Но расчет лексических векторов по обученной модели занимает доли секунды, что делает нейронные сети очень эффективным инструментом.
В нашей работе использовалась векторная модель, обученная по объединенному корпусу НКРЯ и Википедии за декабрь 2018, содержащему 788 миллионов слов. Национальный корпус русского языка (НКРЯ) – это постоянно растущая коллекция текстов на русском языке, имеющая в настоящее время общий объем около 1,5 млрд слов (ruscorpora.ru). С помощью этой векторной модели была построена семантическая карта отношений между словами, представленная на Рис. 2, которая позволила выявить семантические кластеры.
4. Алгоритм PCA. Картинки, которые получились
Для визуализации и построения семантических карт мы использовали метод главных компонент (principal component analysis, PCA). Алгоритм PCA выбирает самое важное направление (компонент, признак, черту, особенность), которая максимально сохраняет информацию о введенных терминах/данных. Если признаки слов располагаются как в эллипсе (см. Рис.1), то PCA выбирает вначале большую ось эллипса.
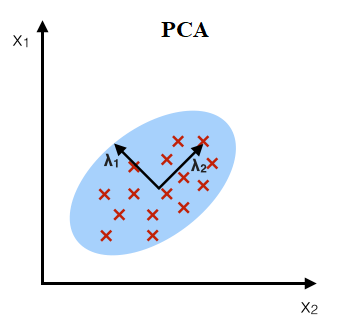
Рисунок 1 - Алгоритм РСА: главные компоненты, которые максимизируют дисперсию
5. Какие эксперименты? Что они доказывают?
Был проведен эксперимент по визуализации слов на темы этики (добро – зло) и эстетики (красивый – некрасивый). В первом визуализируемые слова относились к четырем темам: тема 0 - Добро, тема 1 – Зло, тема 2 – Красивый, тема 3 – Некрасивый. Каждая тема содержала следующие слова.
Тема 0 – ангел, здоровье, истина, бог, жизнь, вера, добро, любовь, благополучие, забота, счастье, добродетель, мудрость, доброта.
Тема 1 – убийство, преступление, смерть, обман, сатана, ложь, ненависть, зло.
Тема 2 – интересный, увлекательный, вкусный, ароматный, хороший, приятный, красивый, отличный, прекрасный.
Тема 3 – ужасный, неприятный, противный, плохой, невкусный, некрасивый.
Использование алгоритма РСА обеспечило представление каждой темы в виде отдельного кластера (см. Рис. 2)
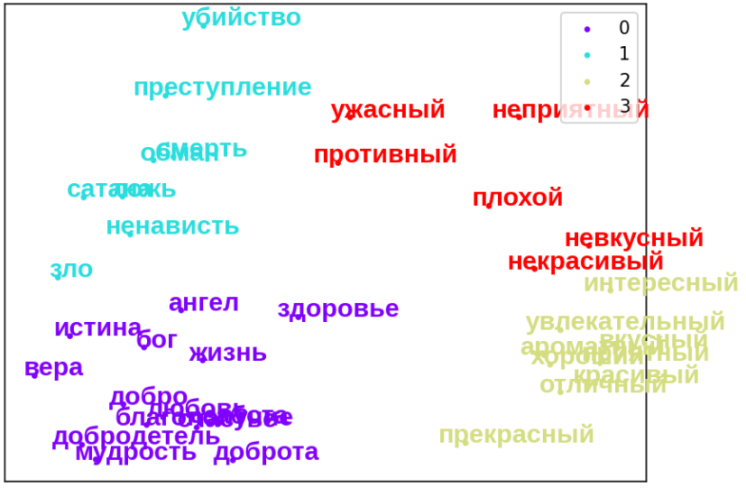
Рисунок 2 - Визуализация с помощью алгоритма РСА слов:
/0/ – ангел, здоровье, истина, бог, жизнь, вера, добро, любовь, благополучие, забота, счастье, добродетель, мудрость, доброта;
/1/ – убийство, преступление, смерть, обман, сатана, ложь, ненависть, зло;
/2/ – интересный, увлекательный, вкусный, ароматный, хороший, приятный, красивый, отличный, прекрасный;
/3/ – ужасный, неприятный, противный, плохой, невкусный, некрасивый
Из анализа визуализаций можно сделать вывод о распределении этических терминов по отдельным областям с различной плотностью. На рисунке 2 этические термины сосредоточены в областях, разделенных пустым пространством. Каждая область соответствует кластеру. Это похоже на галактики, в которых звезды сосредоточены под действием сил притяжения.
Следует также отметить, что кластер Добро ближе расположен к Красивый, а Зло к Некрасивый. Направление вектора Добро – Зло примерно совпадает с направлением вектора Красивый – Некрасивый. Крайние точки (диапазоны) кластеров: мудрость – ангел, зло – убийство, прекрасный – интересный, некрасивый – ужасный.
6. Заключение
На Рис. 2 представлена «словесная карта», которая представляет основной полученный результат. Авторы интерпретируют его следующим образом.
Алгоритм PCA сначала выбирает главное (с его точки зрения) направление – низ вверх, – по которому выстраивает термины. В результате этого образуется два кластера: Хорошее и Плохое (Хорошее – внизу, Плохое – вверху). В эти два кластера входят как этические термины (любить, добрый, ненавидеть, ложь), так и эстетические (красивый, ароматный, неприятный, грязный). Иначе говоря, на первом уровне анализа смешивается этика с эстетикой. Но на втором уровне анализа алгоритм PCA выбирает вспомогательное направление (право-лево) благодаря которому происходит более тонкий анализ, в результате чего образуется четыре кластера Добро, Зло, Красивый, Некрасивый (на Рис. 2 они показаны соответственно фиолетовым, голубым, зеленым и бежевым цветами). Таким образом, двухуровневый анализ не только выделяет этические кластеры Добро, Зло, но и эстетические кластеры Красивый, Некрасивый.
Отсюда можно сделать вывод, что эти кластеры реально присутствуют в языке. Поэтому нельзя сказать что «все в мире относительно» как это делали в древнем мире софисты (идея радикального релятивизма), т.к. «Если бы было все равно» и все относительно, то зло бы перемешивалось с добром и нельзя было бы понять отличие одного от другого и не видно было бы двух явно различающихся кластеров на рисунках. Релятивизм софистов (напр., утверждение о возможности доказать и правильность, и неправильность любого положения в зависимости от обстоятельств) не подтверждается семантикой языка.
Если обратиться к наиболее авторитетной моральной системе – христианству, то мы обнаружим, что добро и зло в мире носят абсолютный характер; в моральном плане все сущее разделяется на две сферы – сферу добра и сферу зла.
Но интересно, что полученные результаты говорят о том, что аналогичный характер носит и разделение КРАСИВЫЙ / НЕКРАСИВЫЙ. Красота абсолютна и относительность красоты не находит воплощения в мышлении и языке. Как тут не вспомнить мысль нашего выдающегося философа Владимира Сергеевича Соловьева о синтезе истины, добра и красоты. Видимо тут Соловьев имел в виду не семантическое тождество, а то, что по отношению к абсолютности эти понятия ведут себя одинаково.
Именно такой принципиальной противоположностью сфер добра и зла (а также красоты и уродства) и объясняется разделение всех терминов на два достаточно четко очерченных кластера. Однако резкого разделения кластеров мы не видим. По нашему мнению, причина лежит в том, что зло, чтобы существовать в этом мире, вынуждено маскироваться под силы добра, так что, как сказано в Новом Завете: «сам сатана принимает вид Ангела света» (2 Кор.11,14). Эта сложность приводит к путанице как на ментальном уровне, так и на языковом, что до некоторой степени отражается на результатах приводимых экспериментов. Такое явление, обычно называемое как эстетизация зла, особенно характерно для современной культуры.
Можно указать еще ряд причин нечеткости разделения кластеров. Так, например, богословами давно показано, что Бог не является источником зла, но Он умеет злые деяния в конце концов обращать в добро, в результате чего слово «бог» зачастую попадает в «злые» контексты и не находится на вершине сферы добра, а занимает среднее положение (хотя и определенно попадает в кластер добра).
Авторы предполагают более тщательно подтвердить полученные результаты. В частности, они планируют изучить вопрос на других дистрибутивно-семантических моделях и других корпусах текстов.