A Bibliometric Analysis of Trending Topics in the English Language Linguistics Research Literature
A Bibliometric Analysis of Trending Topics in the English Language Linguistics Research Literature
Abstract
The work presents a bibliometric analysis of trending topics in the English-language scientific literature in linguistics. The analysis is based on DBLP and PubMed collections of scientific articles as of the beginning of 2023, which contain more than 39 million articles in total. The analysis shows a significant increase (more than 3-fold) in the number of English-language papers on linguistics over the 10 years from 2012 to 2022. Trending keywords with predicted long-term trend growth were also identified. Groups of trending words that frequently occur together in article titles form trending topics. Three trending topics in linguistics are examined:
1) natural language, integration and decision-making;
2) biases and complexity;
3) education and competences.
Keywords from each trending topic are provided, and relevant research works are examined.
1. Введение
В данной статье представлен библиометрический анализ трендовых тем в англоязычной научной литературе по лингвистике. Анализ выполнен на основе коллекций научных статей DBLP и PubMed на начало 2023 года, которые содержат суммарно более 39 миллионов статей и свободно представлены в Интернете. Библиометрический анализ использует прогноз трендов ключевых слов, выполненный по методике, описанной в работах
, с применением пакета машинного обучения CatBoost . В результате библиометрического анализа выявлены трендовые ключевые слова, которые имеют долгосрочный прогноз роста их трендов, и построен рейтинг таких слов. Результаты прогноза были визуализированы с помощью алгоритма t-SNE, что позволило определить трендовые темы, содержащие кластеры трендовых слов.Статья имеет следующую структуру. В разделе ниже описаны результаты библиометрического анализа, далее приводится обзор научной литературы по выявленным трендовым темам в лингвистике. В конце дается заключение.
2. Библиометрический анализ
Библиографический анализ был проведен на базе коллекций PubMed и DBLP-v13. Коллекция DBLP-v13 содержит 5,354,309 статей в области компьютерных наук, а коллекция PubMed по состоянию на начало 2023 года содержала более 34 миллионов статей по медицине, биологии и связанным наукам. Из этих коллекций было выделено 13640 заголовков научных статей, содержащих слова linguistic (лингвистический), linguistics (лингвистика) или linguistically (лингвистически). Эти заголовки статей были найдены по запросу Linguistic*, где звездочка (*) означает любую последовательность букв. Данные 13640 статей мы называем в дальнейшем Выборочной коллекцией. Выборочная коллекция безусловно связана с лингвистикой, т.к. все её статьи в заголовках содержат упоминание лингвистики. В заголовок обычно выносятся слова, имеющие существенное отношение к теме статьи.
В процессе анализа были рассчитаны графики роста количества статей за последние годы (см. рисунок 1), а также характерные/релевантные ключевые слова в Выборочной коллекции и трендовые ключевые слова среди характерных.
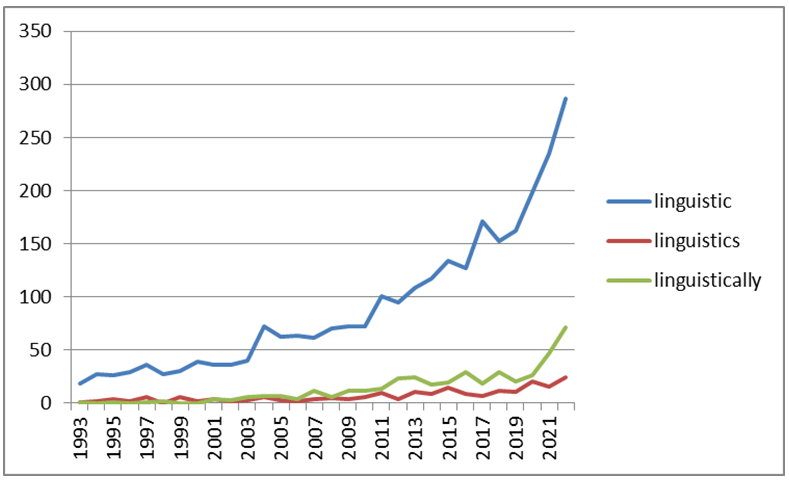
Рисунок 1 - Графики количества научных статей со словами linguistic (лингвистический), linguistics (лингвистика) и linguistically (лингвистически) в коллекциях DBLP и PubMed за различные годы
Характерными/релевантными мы считаем слова, которых относительно много в Выборочной коллекции по сравнению с коллекцией PubMed. Список/рейтинг наиболее характерных ключевых слов в Выборочной коллекции: linguistic (лингвистический), linguistics (лингвистика), linguistically (лингвистически), cross-linguistic (межлингвистический), culturally linguistically (культурно-лингвистический), linguistically diverse (лингвистически разнообразный), fuzzy linguistic (нечеткая лингвистика), computational linguistics (компьютерная лингвистика), linguistic analysis (лингвистический анализ), linguistic validation (лингвистическая проверка), linguistic information (лингвистическая информация), culturally (культурно), linguistic features (лингвистические особенности), linguistic knowledge (лингвистические знания), non-linguistic (нелингвистический), hesitant (нерешительный), linguistic term (лингвистический термин), linguistic approach (лингвистический подход), linguistic preference (лингвистические предпочтения), cultural linguistic (культурно-лингвистический), probabilistic linguistic (вероятностный лингвистический), linguistic processing (лингвистическая обработка), uncertain linguistic (неопределенный лингвистический), hesitant fuzzy (колеблющийся нечеткий), linguistic resources (лингвистические ресурсы), term sets (наборы терминов), linguistic structure (лингвистическая структура), group decision (групповое решение), linguistic data (лингвистические данные), cognitive linguistic (когнитивный лингвистические), linguistic variables (лингвистические переменные), cross-linguistic study (кросс-лингвистическое исследование), linguistic fuzzy (лингвистический нечеткий анализ), linguistic summaries (лингвистические резюме), linguistic cultural (лингвокультура), decision making (принятие решений), multiple attribute (множественный атрибут), preference relations (отношения предпочтений), linguistic diversity (языковое разнообразие), linguistic environment (языковая среда), linguistic complexity (лингвистическая сложность), group decision-making (групповое принятие решений) и т.д.
Долгосрочные прогнозы трендов для характерных ключевых слов были рассчитаны, используя различные показатели для групп статей, содержащих эти ключевые слова. Наиболее важным индикатором тренда ключевого слова является количество цитирований ключевого слова (KЦКC). Для расчета этого показателя мы сначала находим все статьи с этим ключевым словом в определенном году, а затем подсчитываем все цитирующие ссылки на эти статьи. Для каждого слова мы рассчитали продолжительность его трендового роста, равную количеству лет непрерывного роста его средней цитируемости. Такая продолжительность роста тренда была целью для алгоритма машинного обучения CatBoost
. Регрессионная модель CatBoost была обучена для 20 параметров тренда ключевого слова в текущем и предыдущих годах, включая: текущий KЦКC, общее количество статей с ключевым словом, количество лет роста предыдущего тренда, общий рост цитируемости для предыдущего тренда, количество лет от начала тренда, количество цитирующих связей между статьями со словом, время от трендовой ситуации до текущего года. Более подробно данная методика описана в работах , .С помощью алгоритма машинного обучения CatBoost были рассчитаны долгосрочные прогнозы растущих трендов для характерных слов и построен следующий рейтинг трендовых ключевых слов в Выборочной коллекции: deficit (дефицит), competence (компетентность), preschool (дошкольный возраст), bias (предвзятость), integrating (интеграция), aggregation (агрегирование), patient-reported (по сообщениям пациентов), decision making (принятие решений), retrieval (извлечение), ***, annotation (аннотация), predicts (прогнозирует), arabic (арабский язык), autism (аутизм), complexity (сложность), genetic diversity (генетическое разнообразие), online (онлайн), fuzzy (нечеткий), questionnaire (анкета), foreign language (иностранный язык), context (контекст), dyslexia (дислексия), listening (аудирование), natural language (естественный язык), verbal (вербальный), *****, autism spectrum (спектр аутизма), culturally (культурно), emotional (эмоциональный), overactive (гиперактивный), brainstem (ствол мозга), individual differences (индивидуальные различия), linguistic (лингвистический), dialogue (диалог), speech therapy (логопед), parsing (синтаксический анализ), language learning (изучение языка), lateralization (латерализация), working memory (рабочая память), linguistics (лингвистика), linguistically (лингвистически), group (групповой), fuzzy linguistic (нечеткой лингвистики), computational linguistics (компьютерной лингвистики), cross-linguistic (кросслингвистический) и т.д. В начале данного рейтинга расположены ключевые слова с наиболее долгосрочным прогнозом роста трендов. Рейтинг разделен на три группы с помощью меток *** и *****, которые стоят в конце первой и второй группы. Первая группа содержит 9 терминов, вторая – 15, а третья – 19. Деление на группы условно и определяется наглядностью визуализации. Термины из первой группы отображаются на рисунке 2 красным цветом, из второй – синим, из третьей – черным.
Далее рассчитали совместную встречаемость характерных ключевых слов/терминов в заголовках статей в Выборочной коллекции, а также их меру близости – чем чаще термины встречаются вместе, тем меньше семантическое расстояние. По этим данным была построена семантическая карта с помощью алгоритма t-SNE (см. рисунок 2).
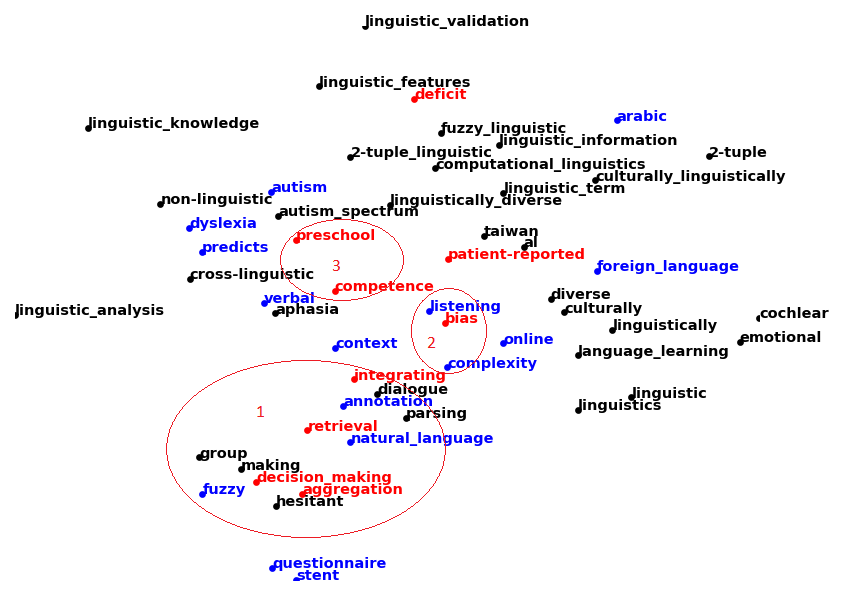
Рисунок 2 - Семантическая карта терминов из предметной области «Лингвистика»:
красным цветом выделены наиболее перспективные/трендовые термины, имеющие долгосрочные тренды; синим – средние тренды; черным – минимальные тренды
Примечание: чем чаще термины встречаются вместе в заголовках статей, тем ближе они расположены на рисунке; группы рядом расположенных трендовых терминов образуют трендовые темы
Итак, на рисунке 2 видны три трендовые темы в лингвистике. Этим трендовым темам можно дать следующие названия:
1) естественный язык, интеграция и принятие решений;
2) предубеждения и сложность;
3) образование и компетенции.
В следующем разделе опишем более подробно эти трендовые темы.
3. Обзор трендовых тем
Рассмотрим три трендовых темы в лингвистике, выявленные в процессе библиометрического анализа.
К первой теме «естественный язык, интеграция и принятие решений» относятся статьи из области компьютерной лингвистики и обработки естественного языка. Эта тема имеет следующие ключевые слова, выделенные красным цветом на рисунке 2: интеграция (integrating), принятие решений (decision making), поиск (retrieval), агрегирование (aggregation).
Рассмотрим некоторые статьи из этой темы. В статье
рассматривается интеграция нескольких типов неполных отношений лингвистических предпочтений в процессе принятия решений несколькими людьми. Работа посвящена методам лингвистической агрегации при поиске по блогам. В статье рассматривается метод на основе кластеризации для принятия решений в больших группах с неуверенной нечеткой лингвистической информацией. Метод разделяет экспертов на несколько кластеров. Использование кластеризации одновременно обеспечивает сплоченность кластеров и постепенное повышение уровня коллективного консенсуса при принятии решений.Ко второй трендовой теме «предубеждения и сложность» относятся статьи, в которых рассматриваются вопросы, связанные с построением лингвистических моделей, а также с лингвистическими предубеждениями и лингвистической сложностью. Эта тема имеет следующие ключевые слова, выделенные красным и синим цветами: предвзятость (bias), сложность (complexity). Термин «complexity» изображен на рисунке 2 синим цветом, но он также является трендовым и к тому же находится ближе к началу второй группы в рейтинге трендовых ключевых слов.
Рассмотрим некоторые статьи из этой трендовой темы. В статье
обсуждаются лингвистические модели для анализа и обнаружения предвзятой речи. Работа посвящена методам обнаружения предвзятости посредством анализа настроений и простых лингвистических функций. В статье рассматривается влияние алгоритмической предвзятости на лингвистическую сложность машинного перевода. Авторы предполагают, что «алгоритмическая погрешность», т.е. обострение часто наблюдаемых закономерностей в сочетании с утратой менее частых не только усугубляет социальные предубеждения, присутствующие в текущих наборах обучающих текстовых данных, но также приводит к искусственно обеднённому языку машинного перевода. Авторы оценивали лингвистическое богатство (на лексическом и морфологическом уровне) переводов, созданных с помощью различных парадигм машинного перевода и показали, что происходит потеря лексического и морфологического богатства в переводах, произведенных всеми исследованными парадигмами машинного перевода для двух языковых пар (EN↔FR и EN↔ES).Третья трендовая тема «образование и компетенции» содержит статьи, в которых, в частности, рассматриваются вопросы, связанные с анализом лингвистических компетенций учащихся и оценки профессионального развития компетентности у преподавателей. Эта тема имеет следующие ключевые слова: дошкольный возраст (preschool), преподаватели (teachers), языковые компетенции (linguistic competence).
Рассмотрим некоторые статьи, относящиеся к этой трендовой теме. В статье
исследуется взаимодействие зрительной информации, вербальной информации и языковой компетенции у ребенка дошкольного возраста. Работа посвящена методам принятия решений по множественным признакам с неуверенной нечеткой неопределенной лингвистической информацией и их применению для оценки профессионального развития компетентности у преподавателей английского языка колледжей.4. Заключение
В последние десятилетия наблюдается значительный рост количества англоязычных работ по лингвистике. Так, за 10 лет с 2012 по 2022 количество таких работ в многомиллионных коллекциях PubMed и DBLP выросло более чем в три раза. Стремительно развиваются такие направления лингвистики, как компьютерная лингвистика, нечеткая лингвистика, построение лингвистических моделей, анализ лингвистических предубеждений, методы обучения иностранным языкам и другие. В результате прогнозного библиометрического анализа выявлены следующие три трендовых направления в англоязычной научной литературе по лингвистике:
1) естественный язык, интеграция и принятие решений;
2) предубеждения и сложность;
3) образование и компетенции.