Визуальные структуры как средства референции в мультимодальном юмористическом тексте (на примере американских сатирических мультсериалов)
Визуальные структуры как средства референции в мультимодальном юмористическом тексте (на примере американских сатирических мультсериалов)
Аннотация
Настоящая работа посвящена исследованию вопроса об осуществлении референции в мультимодальном юмористическом тексте. Репрезентативным материалом исследования послужили эпизоды американских сатирических мультсериалов «South Park» и «Family Guy». Анализ репрезентативного материала позволил установить, что в исследуемых мультимодальных юмористических текстах указание на участников изображаемой ситуации осуществляется посредством визуальных структур, а конкретно аналитических структур. Было установлено, что именно характерные особенности данных структур позволяют указать на принадлежность участника ситуации к классу или группе (представители профессии, национальности, религии, социальной группы и пр.), или же идентифицировать его как реально существующее лицо. Проведенный анализ позволил сделать вывод о роли визуальных структур в осуществлении референции и механизмах её реализации.
1. Введение
Понятие мультимодальности пришло в лингвистику из социальной семиотики, назначение которой её основоположник М. Хэллидей определял как «рассмотрение языка через призму социокультурного контекста, в котором сама культура рассматривается в терминах семиотики, как информационная система» Социо-семиотическая теория в дальнейшем получила развитие в работах Г. Кресса и Т. ван Лейвена. В рамках этой теории был выдвинут тезис о том, что коммуникация мультимодальна потому, что в ней всегда задействуются одновременно несколько модусов и модальностей . Под термином «модус» понимается способ построения значений с использованием принятых в конкретной культуре семиотических ресурсов (визуальный модус, вербальный модус, жестовый модус и пр.) . Термин «модальность» указывает на способ построения значения в знаке для выражения достоверности суждения о мире, в социо-семотическом подходе выражение модальности возможно не только языковыми, но и визуальными, аудиальными и другими средствами . Интересно, что в отечественной лингвистике термин «модальность» принято в большей степени связывать с каналом коммуникации, который оказывается задействован при передаче и восприятии сообщения . Таким образом, понятие «мультимодальность» означает порождение значений (смыслов), при помощи комбинации разных семиотических ресурсов и использования разных каналов . Cоответственно, говоря о мультимодальном тексте, мы имеем в виду текст, который образован при помощи задействования нескольких разных модусов и нескольких каналов коммуникации.
Мультимодальные тексты юмористического характера (видеоролики, интернет-мемы, карикатуры и пр.) сегодня являются важной частью интернет-коммуникации: они размещаются на различных платформах, сайтах и социальных сетях, пересылаются в процессе онлайн-общения. Важной особенностью такой коммуникации является её опосредованный характер (автор-создатель юмористического видео или интернет-мема не взаимодействует напрямую с адресатом) . При этом, автору необходимо обеспечить усвоение адресатом полученной информации: идентифицировать изображаемую в тексте ситуацию и её участников и распознать комический эффект.
В связи с этим цель настоящей работы состоит в том, чтобы описать способы осуществления референции, т.е., указания на объекты действительности, в частности, на участников ситуации, в мультимодальных юмористических текстах. Исследование вопроса о соотношении слова и действительности имеет долгую историю, его решение предлагалось прежде всего в семиотике: слово (знак) обозначает предмет (референт или денотат) посредством понятия . В современной лингвистической семантике принято считать, что языковому знаку соответствует денотат, т.е., информация о внеязыковой действительности. Денотат выступает в двух модификациях: виртуальный денотат содержит множество объектов, которые могут именоваться данным выражением, а актуальный денотат (референт) — только тот предмет или объект действительности, который имеет во ввиду говорящий в коммуникации .
Таким образом, референцию принято понимать как отношение имени к объекту, им называемому , или же как соотнесенность актуализированных, (включенных в речь) имен, именных выражений (именных групп) или их эквивалентов к объектам действительности (референтам, денотатам) . Коммуникативная функция референтного выражения состоит прежде всего в указании на предмет, о котором cообщается в высказывании (процесс идентификации) . Референция может осуществляться посредством любых языковых выражений .
В мультимодальном тексте не только языковые выражения (средства вербального модуса) участвуют в референции, но и изображение (средства визуального модуса). Такими средствами являются визуальные структуры
, и в настоящей работе будут представлены результаты исследования их роли в осуществлении референции и обеспечении идентификации участников ситуации в мультимодальном юмористическом тексте.2. Методы и принципы исследования
Теоретико-методологическую базу исследования составили работы по теории референции (Падучева, Арутюнова), теории мультимодальности (Хэллидей, Кресс, ван Лейвен), а также по визуальным структурам и их классификации (Кресс, ван Лейвен). Был отобран репрезентативный материал, включающий в себя англоязычные мультимодальные тексты юмористического характера (американские мультсериалы «South Park», 10 эпизодов, и «Family Guy», 10 эпизодов). В ходе анализа репрезентативного материала было установлено три группы участников изображаемой ситуации:
1. Постоянные персонажи сериалов.
2. Реально существующие публичные лица, изображенные в сериале.
3. Эпизодические или второстепенные персонажи сериала.
Были установлены виды визуальных структур, примененные для указания на участников ситуации и сделан вывод о механизме осуществления референции.
3. Основные результаты
Анализ теоретико-методологической базы показал, что структуры визуального модуса в мультимодальных текстах разделаются на две большие группы: нарративные и концептуальные . Нарративные структуры характеризуются наличием участников изображаемой ситуации, которые могут выполнять семантическую функцию Актора (инициатора действия) или Цели (того, на кого направлено действие), и наличием вектора действия, от Актора к Цели (см. рис. 1). Для динамических мультимодальных текстов вообще, и для отобранного материала в частности, характерно, что в состав нарративных структур входят концептуальные аналитические структуры.

Рисунок 1 - Пример нарративной структуры
Примечание: стрелкой показан вектор – действие (говорение, наставление) направлено от Актора к Цели; кадр из 4 серии 6 сезона мультсериала «Family Guy»
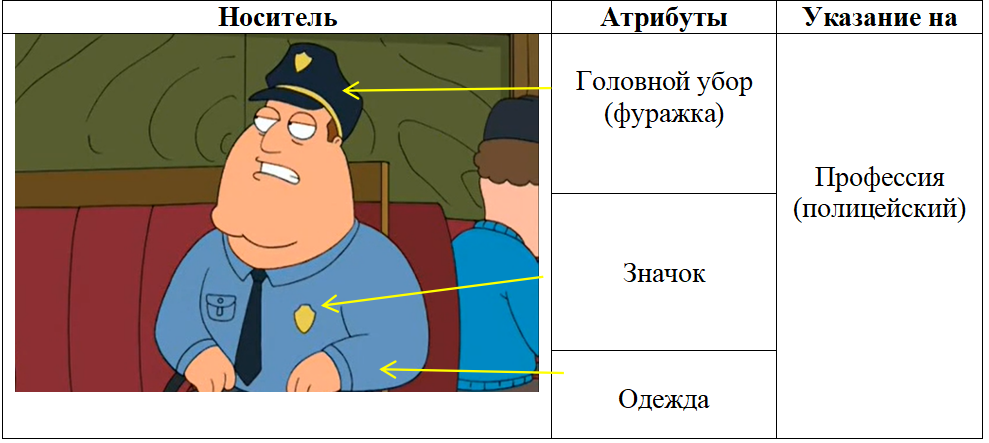
Рисунок 2 - Пример аналитической структуры
Примечание: кадр из 8 серии 5 сезона мультсериала «Family Guy»
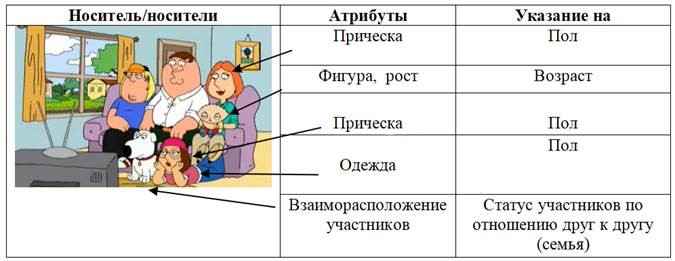
Рисунок 3 - Пример использования аналитической структуры для первичного указания на постоянных персонажей
Примечание: кадр из 1 серии 1 сезона мультсериала «Family Guy
При указании на участника ситуации из группы «реально существующие публичные лица, изображенные в сериале», атрибуты носителя в аналитических структурах служат для сообщения такой информации, которая позволит адресату идентифицировать участника ситуации как объект реальной (а не изображаемой в сериале) действительности и соотнести его с именем собственным, которое использовалось для указания на этого участника либо до его появления на экране, либо после. Для достижения этой цели используется изображение наиболее узнаваемых черт внешности человека (см. рис. 4).
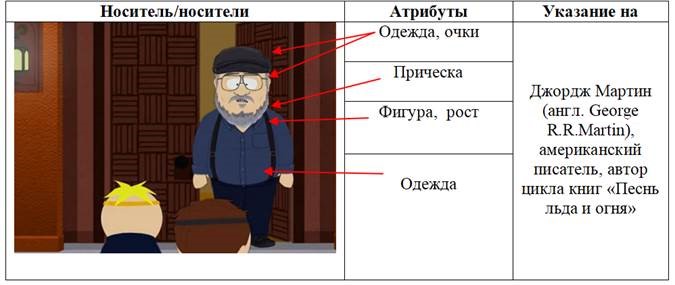
Рисунок 4 - Пример использования аналитической структуры для указания на реально существующее лицо
Примечание: кадр из 7 серии 17 сезона мультсериала «South Park»
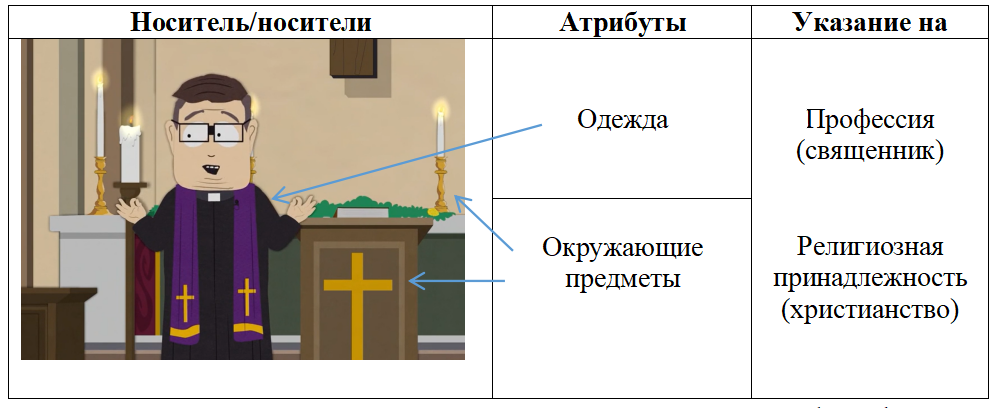
Рисунок 5 - Пример использования аналитической структуры для сообщения информации об эпизодическом персонаже
Примечание: кадр из 2 серии 22 сезона мультсериала «South Park»
4. Обсуждение
Полученные результаты позволили установить, что в мультимодальном тексте визуальные аналитические структуры используются для указания и идентификации участника изображаемой ситуации. При этом интересно проанализировать полученные данные с точки зрения референциальных типов, подробно описанных в отечественной теории референции , .
Применительно к средствам вербального модуса (языковым выражениям), установлено, что существуют различные именные группы, обладающие определенным референциальным статусом, т.е., возможностью осуществлять типы референции. В частности, выделяются конкретно-референтные именные группы (конкретная референция, включающая в себя определенный и неопределенный виды), и неконкретно-референтные именные группы (неконкретная референция, включающая универсальные, атрибутивные и родовые виды) .
Определенный тип референции осуществляется, когда говорящий считает, что существует единственный объект, удовлетворяющий дескрипции: он считает также, что этой дескрипции удовлетворяет объект, который он имеет в виду . Данный тип cопоставим с той референцией, которая осуществляется в мультимодальном тексте при соотнесении аналитической визуальной структуры с реально существующим лицом, или с конкретным, уже известным адресату персонажем сериала.
При родовом типе референции именная группа соотносится либо с классом объектов (с экстенсионалом общего имени), либо с эталонным, типичным представителем класса . В мультимодальном тексте данный тип сопоставим с референцией, которая осуществляется, когда аналитическая структура соотносит изображаемого персонажа с классом лиц (объектов): представителей профессии, национальности, религии, социальной группы и пр.
Важно отметить также взаимосвязь вербальных средств и аналитических структур. В рассмотренном материале в качестве вербальных средств для указания на участников ситуации использовались имена собственные (имена персонажей сериала или имена реально существующих лиц). Известно, что имя собственное не имеет значения в языке, и потому его референция обычно основана не на его смысле, а на внеязыковых знаниях говорящего
. Аналитическая структура, использующаяся совместно с именем собственным, позволяет актуализировать эти знания, соотнести имя с объектом и таким образом установить определенную референцию к нему. При указании на эпизодических персонажей аналитические структуры также позволяют соотнести имя собственное с визуальным образом, а также осуществляют родовую референцию и позволяют отнести носителя имени к классу определенных лиц (объектов) по признаку профессии, социального класса, происхождения и пр.5. Заключение
В мультимодальном юмористическом тексте аналитические визуальные структуры, состоящие из носителя и его атрибутов, используются для указания на участников изображаемой ситуации. Атрибуты носителей в этих структурах позволяют сообщить информацию о значимых свойствах объекта, которые обеспечивают распознавание его образа у получателя, соотнести имя с объектом, о котором идет речь, или позволяют идентифицировать его как представителя определенного класса лиц (объектов) или реально существующее лицо.
Проведенное исследование позволило установить, что в визуальном модусе аналитические структуры используются для осуществления типов референции, которые ранее были установлены для именных групп вербального модуса: конкретной (определенной) и неконкретной (родовой) референции. Полученные результаты позволили наметить направления дальнейших исследований, в том числе, изучения вопроса о том, возможно ли осуществление других типов референции визуальными средствами в мультимодальном тексте.